GPU 与英伟达
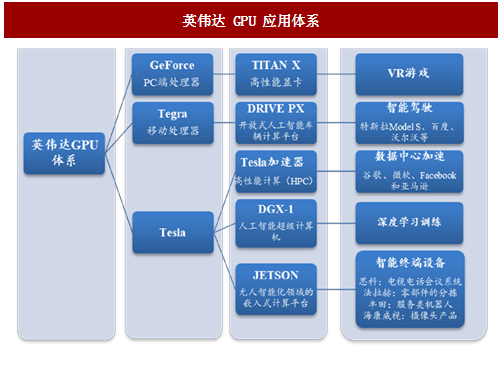
英伟达的产品广泛应用于数据中心、智能驾驶等领域。目前英伟达的GPU产品主要应用于各类计算平台、数据中心加速和深度学习训练,应用领域包括医疗、汽车、智能家电、金融服务等各个行业。公司利用自身的优势GPU产品开发了一系列应用系统。基于Tegra系列处理器,英伟达发布了DRIVE PX开放式人工智能车辆计算平台,可实现包括高速公路自动驾驶与高清制图在内的自动巡航功能,且搭载了Tegra K1处理器并应用了DRIVEPX计算平台的智能汽车特斯拉Model S 已经开始量产,而百度、沃尔沃也跟英伟达达成了合作,他们都将生产搭载DRIVE PX 2的智能驾驶汽车。
Tesla 系列 GPU 是目前 GPU 参与 AI 计算中最前沿、应用最广泛的。基于Tesla 系列处理器,其最基础也是最重要的应用是对数据中心进行计算加速,Tesla 加速器拥有高性能计算 (HPC) 和超大规模工作负载的能力,能在降低数据中心成本同时,大幅提高数据中心吞吐量。谷歌、微软、Facebook 和亚马逊等技术巨头都使用英伟达的芯片来扩充自己数据中心的处理能力;深度学习训练方面,英伟达2016年上半年推出人工智能超级计算机DGX-1,应用Tesla P100芯片,能够快速设计深度神经网络,性能相当于 250 台传统服务器,可以将深度学习的训练速度加快75倍,将CPU性能提升56倍。
JETSON而同样基于Tesla的另一系列产品JETSON则是面向无人智能化领域的嵌入式计算平台,适合机器人、无人机、智能摄像机和便携医疗设备等智能终端设备。目前JETSON系列产品的应用案例包括思科的电视电话会议系统(人脸识别、智能识别)、法拉赫的工厂自动化(零部件的分拣)、丰田的服务类机器人、海康威视的摄像头产品等。
FPGA 成为 ADAS 主要处理平台,在各行业为差异化产品提供算力。FPGA高密度计算、大吞吐量和低功耗的特点,其在各个行业领域较大的发展空间。FPGA 的传统应用领域主要在通信和无线设备系统,为数据中心提供更高的能源效率,更低的成本和更高的扩展性。
参考中国报告网发布《2018-2023年中国人工智能芯片市场发展现状与发展机遇分析报告》
Xilinx在通信与无线设备领域已经开始布局5G的可编程解决方案,除此之外,Xilinx 和 Altera均在工业、汽车、医疗、消费电子、广播、军事等行业有FPGA应用的实例。如在工业领域可实现自动化、机器视觉和运动控制;在汽车领域则成为ADAS的主要处理平台,提供实施图像分析与智能传输。由于FPGA的可编程性,其在各个行业提供差异化产品和快速响应上有着极大的优势。
CPU+FPGA 的混合结构成为 Intel 的主推的云服务计算架构。2015年12月英特尔以167亿美元收购Altera,整合Altera的FPGA技术以及英特尔自身在CPU方面的优势,推出CPU + FPGA 异构计算产品,力图在摩尔定律的尽头,用FPGA 提升CPU的效能比,实现深度学习的预测环节。在预测环节,海量的预测请求是高密度计算,不同于GPU所擅长的高性能计算,所以云服务器中CPU+FPGA芯片模式成为了云端预测较优的选择。Xilinx则与IBM和高通签订协议,开展数据中心加速战略合作。在深度学习预测领域Xilinx也推出了面向云端的框架,包含 Xilinx 深度神经网络 (x f DNN) 库,可构建深度学习推断应用。目前,全球云计算服务商纷纷布局云端FPGA的生态,FPGA倍受看好。

寒武纪引动国际 AI 芯片潮流,结合华为麒麟芯片率先实现落地。国内在ASIC领域领先的企业为刚刚获得1亿美元A轮融资的寒武纪,其开发了国际首个深度学习专用处理器芯片(NPU),同时其背后的学术理论与技术(尤其是指令集)在全球范围内引起了广泛的讨论,AI芯片领域的大量新发学术论文均借鉴了寒武纪两位主要成员的学术论文。
目前公司的产品主要包括三种处理器结构:寒武纪1号(Dian Nao,面向神经网络的原型处理器结构);寒武纪2 号(Da Dian Nao,面向大规模神经网络);寒武纪 3 号(Pu Dian Nao,面向多种机器学习算法)。其中, Dian Nao是寒武纪系列的第一个处理器结构,包含一个主频为0.98GHz的核,峰值性能达每秒 4520 亿次神经网络基本运算,65nm 工艺下功耗为 0.485W,面积 3.02mm2,目前已经衍生出 1A、1H等系列。其中,华为最新发布的麒麟970 处理器中搭载的就是 Cambricon-1A Processor 型号芯片。根据披露的数据显示, Dian Nao的平均性能超过主流CPU核的100倍,但是面积和功耗仅为1/10,效能提升可达三个数量级;Dian Nao 的平均性能与主流 GPGPU 相当,但面积和功耗仅为主流GPGPU百分之一量级。
寒武纪三条产品线共同发展。寒武纪的执行董事公开表示,目前公司设立了三条产品线:一是智能终端处理器的IP 授权。智能 IP 指令集可授权集成到手机、可穿戴设备、摄像头等终端芯片中,客户包括国内顶尖SoC厂商,目前已经开始投入市场。2016年全年就已拿到1个亿元订单,在成立首年就实现盈利。其次,在智能云服务器芯片领域可以作为PCI-E加速卡配合云服务器,客户主要是国内的知名服务器厂商。另外,从智能玩具、智能助手入手,帮助服务机器人独立具备看听说的能力,客户是各类下游机器人厂商,产品的推出将比智能云服务器芯片更晚一些。

True North 是 IBM 潜心研发近 10 年的类脑芯片,也是目前类脑芯片的代表。
2011年类脑芯片首次发布,IBM通过模拟大脑结构,研制出两个具有感知认知能力的硅芯片原型,具有大规模并行计算能力。2014 年,IBM 公司发布了True North 的第二代类脑芯片。True North 芯片性能大幅提升,其神经元数量由 256 个增加到 100万个;可编程突触数量由 26万个增加到 2.56 亿个;每秒可执行 460 亿次突触运算,总功耗为 70 mW,每平方厘米功耗 20 mW,处理核体积仅为第一代类脑芯片的 1/15。目前,IBM 公司已开发出一台神经元计算机原型,它采用 16 颗 True North 芯片,具有实时视频处理能力。
Zeroth 则是高通公司近几年开始研究的“认知计算平台”,它可以融入到高通公司量产的 Snapdragon 处理器芯片中,以协处理的方式提升系统的认知计算能,并可实际应用于手机和平板电脑等设备中,支持诸如语音识别、图像识别、场景实时标注等实际应用并且表现卓越。

英伟达目前引领者 GPU 在 AI 计算领域的风向。GPU是目前在AI计算领域应用最早最成熟的通用型芯片,而英伟达是 GPU 芯片市场的绝对龙头,占据了 70% 以上的市场份额,GPU在人工智能领域的应用一直由英伟达引领。英伟达的GPU 产品主要包括PC端处理器GeForce、移动处理器Tegra和深度学习芯片Tesla,不同的GPU种类适用于人工智能领域不同的智能计算设备。其中Tesla的核心产品包括基于PASCAL架构和 Volta架构的Tesla系列芯片,为资料中心带来最高的能源效率,为深度学习作业负载带来最大的处理量。
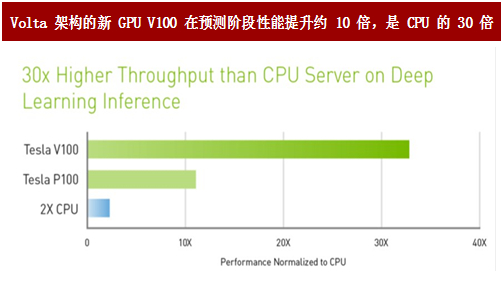
最新的 Volta 架构使得 GPU 在预测阶段的效率也大大提升。英伟达最在美国时间 5月10日发布了新一代专门针对AI计算设计的GPU架构 Volta,其核心改进使得 Tesla系列芯片在深度学习预测阶段的性能得到大大提升,推理性能提升约10 倍,在这一架构下GPU不仅在训练结算具有绝对优势,在预测推理场景也能成为不错的商用选择。相比上一代Pascal架构GPU,新品的晶体管数目增加了38%,达到了惊人的211亿个;核心面积也继续增加33%,几乎已经达到了制造工艺极限。随着核心的增大,新品的的单、双精度浮点性能也大幅提升了41%,这也体现了英伟达意欲称霸AI芯片的决心,不断地提高产品的护城河。
图:Volta 架构的新 GPU V100 在预测阶段性能提升约 10 倍,是 CPU 的 30 倍
英伟达的产品广泛应用于数据中心、智能驾驶等领域。目前英伟达的GPU产品主要应用于各类计算平台、数据中心加速和深度学习训练,应用领域包括医疗、汽车、智能家电、金融服务等各个行业。公司利用自身的优势GPU产品开发了一系列应用系统。基于Tegra系列处理器,英伟达发布了DRIVE PX开放式人工智能车辆计算平台,可实现包括高速公路自动驾驶与高清制图在内的自动巡航功能,且搭载了Tegra K1处理器并应用了DRIVEPX计算平台的智能汽车特斯拉Model S 已经开始量产,而百度、沃尔沃也跟英伟达达成了合作,他们都将生产搭载DRIVE PX 2的智能驾驶汽车。
Tesla 系列 GPU 是目前 GPU 参与 AI 计算中最前沿、应用最广泛的。基于Tesla 系列处理器,其最基础也是最重要的应用是对数据中心进行计算加速,Tesla 加速器拥有高性能计算 (HPC) 和超大规模工作负载的能力,能在降低数据中心成本同时,大幅提高数据中心吞吐量。谷歌、微软、Facebook 和亚马逊等技术巨头都使用英伟达的芯片来扩充自己数据中心的处理能力;深度学习训练方面,英伟达2016年上半年推出人工智能超级计算机DGX-1,应用Tesla P100芯片,能够快速设计深度神经网络,性能相当于 250 台传统服务器,可以将深度学习的训练速度加快75倍,将CPU性能提升56倍。
JETSON而同样基于Tesla的另一系列产品JETSON则是面向无人智能化领域的嵌入式计算平台,适合机器人、无人机、智能摄像机和便携医疗设备等智能终端设备。目前JETSON系列产品的应用案例包括思科的电视电话会议系统(人脸识别、智能识别)、法拉赫的工厂自动化(零部件的分拣)、丰田的服务类机器人、海康威视的摄像头产品等。

图:英伟达 GPU 应用体系
FPGA 与 Xilinx、Altera
Xilinx 和 Intel收购的 Altera 占据了 FPGA 近 9 成市场。FPGA的市场发展迅速,但技术门槛比较高,目前市场上主要为Xilinx(赛灵思)与Altera(阿尔特拉)两家公司主导,2016年Xilinx市场份额达53%,Altera份额达36%,两者占据了约90%的市场,专利达到6000余项。FPGA 成为 ADAS 主要处理平台,在各行业为差异化产品提供算力。FPGA高密度计算、大吞吐量和低功耗的特点,其在各个行业领域较大的发展空间。FPGA 的传统应用领域主要在通信和无线设备系统,为数据中心提供更高的能源效率,更低的成本和更高的扩展性。
参考中国报告网发布《2018-2023年中国人工智能芯片市场发展现状与发展机遇分析报告》
Xilinx在通信与无线设备领域已经开始布局5G的可编程解决方案,除此之外,Xilinx 和 Altera均在工业、汽车、医疗、消费电子、广播、军事等行业有FPGA应用的实例。如在工业领域可实现自动化、机器视觉和运动控制;在汽车领域则成为ADAS的主要处理平台,提供实施图像分析与智能传输。由于FPGA的可编程性,其在各个行业提供差异化产品和快速响应上有着极大的优势。
CPU+FPGA 的混合结构成为 Intel 的主推的云服务计算架构。2015年12月英特尔以167亿美元收购Altera,整合Altera的FPGA技术以及英特尔自身在CPU方面的优势,推出CPU + FPGA 异构计算产品,力图在摩尔定律的尽头,用FPGA 提升CPU的效能比,实现深度学习的预测环节。在预测环节,海量的预测请求是高密度计算,不同于GPU所擅长的高性能计算,所以云服务器中CPU+FPGA芯片模式成为了云端预测较优的选择。Xilinx则与IBM和高通签订协议,开展数据中心加速战略合作。在深度学习预测领域Xilinx也推出了面向云端的框架,包含 Xilinx 深度神经网络 (x f DNN) 库,可构建深度学习推断应用。目前,全球云计算服务商纷纷布局云端FPGA的生态,FPGA倍受看好。

图:全球科技巨头在云端 FPGA 的布局
ASIC 与 Google、寒武纪
Google 的 TPU 被应用于支持人工智能平台和 AlphaGo,最新发布的 2.0 版本在训练阶段有很大提升。ASIC芯片由于其优秀的性能特点,全球各公司逐渐开始研发,目前尚处于起步阶段,比较著名的包括Google的TPU,是一款针对深度学习加速的 ASIC 芯片。第一代 TPU 仅能用于推断(即不可用于训练模型),并在 AlphaGo人机大战中提供了巨大的算力支撑。而目前Google发布的TPU 2.0除了推断以外,还能高效支持训练环节的深度网络加速。寒武纪引动国际 AI 芯片潮流,结合华为麒麟芯片率先实现落地。国内在ASIC领域领先的企业为刚刚获得1亿美元A轮融资的寒武纪,其开发了国际首个深度学习专用处理器芯片(NPU),同时其背后的学术理论与技术(尤其是指令集)在全球范围内引起了广泛的讨论,AI芯片领域的大量新发学术论文均借鉴了寒武纪两位主要成员的学术论文。
目前公司的产品主要包括三种处理器结构:寒武纪1号(Dian Nao,面向神经网络的原型处理器结构);寒武纪2 号(Da Dian Nao,面向大规模神经网络);寒武纪 3 号(Pu Dian Nao,面向多种机器学习算法)。其中, Dian Nao是寒武纪系列的第一个处理器结构,包含一个主频为0.98GHz的核,峰值性能达每秒 4520 亿次神经网络基本运算,65nm 工艺下功耗为 0.485W,面积 3.02mm2,目前已经衍生出 1A、1H等系列。其中,华为最新发布的麒麟970 处理器中搭载的就是 Cambricon-1A Processor 型号芯片。根据披露的数据显示, Dian Nao的平均性能超过主流CPU核的100倍,但是面积和功耗仅为1/10,效能提升可达三个数量级;Dian Nao 的平均性能与主流 GPGPU 相当,但面积和功耗仅为主流GPGPU百分之一量级。
寒武纪三条产品线共同发展。寒武纪的执行董事公开表示,目前公司设立了三条产品线:一是智能终端处理器的IP 授权。智能 IP 指令集可授权集成到手机、可穿戴设备、摄像头等终端芯片中,客户包括国内顶尖SoC厂商,目前已经开始投入市场。2016年全年就已拿到1个亿元订单,在成立首年就实现盈利。其次,在智能云服务器芯片领域可以作为PCI-E加速卡配合云服务器,客户主要是国内的知名服务器厂商。另外,从智能玩具、智能助手入手,帮助服务机器人独立具备看听说的能力,客户是各类下游机器人厂商,产品的推出将比智能云服务器芯片更晚一些。

图:部分 ASIC 专用芯片介绍
类脑芯片与 IBM 和高通
类脑计算芯片因其从结构上逼近人脑的思路,在业界和学界被广泛重视,产品包括欧盟支持的Spinnaker 和 Brain Scale S、斯坦福大学的 Neurogrid、IBM 公司的 True North 以及高通公司的 Zeroth,英特尔、Audience和Nu man ta也推出了神经形态芯片。但总体而言,类脑芯片还没有实现规模的商用,仍是一个比较小众的黑科技。True North 是 IBM 潜心研发近 10 年的类脑芯片,也是目前类脑芯片的代表。
2011年类脑芯片首次发布,IBM通过模拟大脑结构,研制出两个具有感知认知能力的硅芯片原型,具有大规模并行计算能力。2014 年,IBM 公司发布了True North 的第二代类脑芯片。True North 芯片性能大幅提升,其神经元数量由 256 个增加到 100万个;可编程突触数量由 26万个增加到 2.56 亿个;每秒可执行 460 亿次突触运算,总功耗为 70 mW,每平方厘米功耗 20 mW,处理核体积仅为第一代类脑芯片的 1/15。目前,IBM 公司已开发出一台神经元计算机原型,它采用 16 颗 True North 芯片,具有实时视频处理能力。
Zeroth 则是高通公司近几年开始研究的“认知计算平台”,它可以融入到高通公司量产的 Snapdragon 处理器芯片中,以协处理的方式提升系统的认知计算能,并可实际应用于手机和平板电脑等设备中,支持诸如语音识别、图像识别、场景实时标注等实际应用并且表现卓越。

图:全球知名公司研发的类脑芯片
资料来源:中国报告网整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








