参考中国报告网发布《2017-2022年中国芯片产业运营现状及投资战略分析报告》
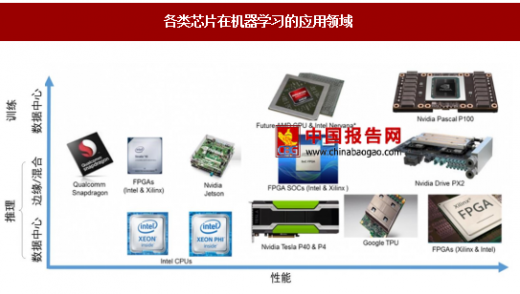
目前用于深度学习的芯片主要类型是GPU、FPGA、ASIC。同时,各家公司也在积极研发专用人工智能专用芯片,例如Google的TPU、IBM的TrueNorth、中星微的NPU、中科院的寒武纪1号等,但离大规模商用化还有一定的距离。

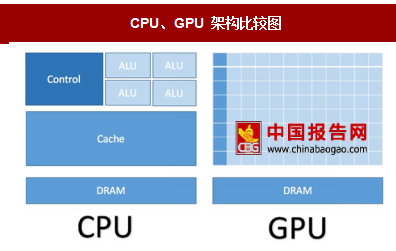
CPU与GPU:由于需要处理各种不同的数据类型,并且逻辑判断需要大量分支跳转和中断处理,因此CPU对于通用性要求很高。这使CPU内部结构较为复杂,留给计算单元(ALU)的面积并不多。而GPU对逻辑控制要求不高,从下图可以看到,GPU80%以上的晶体管都是计算单元,因此它更适合用于海量数据的并行计算。
FPGA与ASIC:两者最大的区别在于,FPGA可以根据需要被配置成不同的器件,而 ASIC则由于是根据用户的特别需求定制的,除灵活性差之外,研发时间也很长,往往需要一年以上的时间,试错成本较高。因此,目前市场上厂商更愿意选择FPGA。
我们认为,在GPU和FPGA之间做取舍时,若FPGA的架构优化能弥补其在峰值性能上的差距,那么FPGA会是更好地选择。原因有2点:
FPGA的灵活性优于GPU:开发者可以根据实际需求对已经制造完成的FPGA芯片进行重新编程。
FPGA较GPU功耗更低、性能更高:英特尔加速器结构实验室(AAL)的Eriko Nurvitadhi博士在《Can FPGAs beat GPUs in Accelerating Next-Generation Deep Neural Networks》论文中以最近表现最佳的NVIDIA Titan X Pascal GPU 为参照,对两代Intel FPGA(Intel Arria10 和Intel Stratix 10)在低精度稀疏DNN算法上的表现进行了对比。测试结果表明,即使在保守的性能假设下,Intel Stratix 10 FPGA性能已经比Titan X GPU提高了约60%,而在中度和积极的性能假设下Stratix 10表现更好,分别提高了2.1和2.3倍。在能耗比方面,Intlel Stratix 10比Titan X要好2.3倍到4.3倍。

目前,英特尔已经推出CPU+FPGA架构。IBM、微软、Facebook、亚马逊、百度、腾讯、阿里的数据中心均已采用FPGA或CPU+FPGA。
根据Tractica预测,深度学习芯片市场收入将从2016年的5.13亿美元增长至2025 年的122亿美元,复合年增长率为42.2%。目前,各家科技巨头都在积极研发人工智能专用芯片。

2017年7月20日, 英特尔推出了Movidius神经计算棒,这是世界上首个基于USB 模式的深度学习推理工具和独立的人工智能(AI)加速器,为广泛的边缘主机设备提供专用深度神经网络处理功能(资料来源:搜狐新闻)。目前,除科技巨头外,诸多创业公司也都开始切入人工智能芯片领域,但该产业需要长期持续的研发投入,并且能够承担较大的试错成本,因此对融资能力要求较高。

资料来源:中国报告网整理,转载请注明出处(ZQ)
目前用于深度学习的芯片主要类型是GPU、FPGA、ASIC。同时,各家公司也在积极研发专用人工智能专用芯片,例如Google的TPU、IBM的TrueNorth、中星微的NPU、中科院的寒武纪1号等,但离大规模商用化还有一定的距离。
CPU/GPU/FPGA/ASIC芯片比较

资料来源:中国报告网整理
CPU与GPU:由于需要处理各种不同的数据类型,并且逻辑判断需要大量分支跳转和中断处理,因此CPU对于通用性要求很高。这使CPU内部结构较为复杂,留给计算单元(ALU)的面积并不多。而GPU对逻辑控制要求不高,从下图可以看到,GPU80%以上的晶体管都是计算单元,因此它更适合用于海量数据的并行计算。
CPU、GPU 架构比较图

资料来源:中国报告网整理
FPGA与ASIC:两者最大的区别在于,FPGA可以根据需要被配置成不同的器件,而 ASIC则由于是根据用户的特别需求定制的,除灵活性差之外,研发时间也很长,往往需要一年以上的时间,试错成本较高。因此,目前市场上厂商更愿意选择FPGA。
我们认为,在GPU和FPGA之间做取舍时,若FPGA的架构优化能弥补其在峰值性能上的差距,那么FPGA会是更好地选择。原因有2点:
FPGA的灵活性优于GPU:开发者可以根据实际需求对已经制造完成的FPGA芯片进行重新编程。
FPGA较GPU功耗更低、性能更高:英特尔加速器结构实验室(AAL)的Eriko Nurvitadhi博士在《Can FPGAs beat GPUs in Accelerating Next-Generation Deep Neural Networks》论文中以最近表现最佳的NVIDIA Titan X Pascal GPU 为参照,对两代Intel FPGA(Intel Arria10 和Intel Stratix 10)在低精度稀疏DNN算法上的表现进行了对比。测试结果表明,即使在保守的性能假设下,Intel Stratix 10 FPGA性能已经比Titan X GPU提高了约60%,而在中度和积极的性能假设下Stratix 10表现更好,分别提高了2.1和2.3倍。在能耗比方面,Intlel Stratix 10比Titan X要好2.3倍到4.3倍。
FPGA 相对于 GPU 耗能更低,性能更高

资料来源:中国报告网整理
目前,英特尔已经推出CPU+FPGA架构。IBM、微软、Facebook、亚马逊、百度、腾讯、阿里的数据中心均已采用FPGA或CPU+FPGA。
根据Tractica预测,深度学习芯片市场收入将从2016年的5.13亿美元增长至2025 年的122亿美元,复合年增长率为42.2%。目前,各家科技巨头都在积极研发人工智能专用芯片。
各家科技巨头人工智能芯片布局

资料来源:中国报告网整理
2017年7月20日, 英特尔推出了Movidius神经计算棒,这是世界上首个基于USB 模式的深度学习推理工具和独立的人工智能(AI)加速器,为广泛的边缘主机设备提供专用深度神经网络处理功能(资料来源:搜狐新闻)。目前,除科技巨头外,诸多创业公司也都开始切入人工智能芯片领域,但该产业需要长期持续的研发投入,并且能够承担较大的试错成本,因此对融资能力要求较高。
部分切入人工智能芯片领域的公司

资料来源:中国报告网整理
各类芯片在机器学习的应用领域

资料来源:中国报告网整理
资料来源:中国报告网整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








